Gemini 3 did not "get smarter with images". It just trains differently 🧠

For engineers and product tech leads who want to understand why Gemini 3 performs so well in visual reasoning and what this means for AI system architecture.
Introduction
Something unusual is happening in real-world tasks: models of roughly the same "size" and training era were trained on similar data volumes, yet Gemini 3 shows a noticeably higher level of visual reasoning - especially on abstract schemes and diagrams.
Most discussions focus on benchmark numbers and marketing phrases like "SOTA on ARC-AGI-2 / MMMU-Pro". For practitioners, this is not very helpful. The real questions are different: which tech stack to choose, how to design pipelines, and where to invest R&D effort.
The gap is not because Google suddenly found "much more data" or a "magic new architecture". The key lies in how the generative part (DiT) and the recognition part (ViT) are connected, and how the model is trained to think through images, not only about images.
This article explains what is behind this shift - from a practitioner's point of view, not a spectator's.
Why the classic ViT hit a ceiling 🚧
ViT as a "one-way parser"
A typical ViT in modern products works like this:
"take an image → convert it to vectors → pass them to the language model".
In this setup:
- the image is just a source of features
- the model rarely checks whether its interpretation is reversible
- there is no pressure to make visual representations suitable for reconstructing the scene
This works well for:
- classification
- decent-quality OCR
- simple diagrams
- "look at the UI and find the button"
But it breaks when tasks require:
- complex spatial logic ("can an object pass through a hole"?)
- understanding geometric constraints
- abstract visual puzzles (for example, ARC-AGI-2)
The reason is simple: the model was never trained to verify its visual understanding by trying to build something back from those representations.
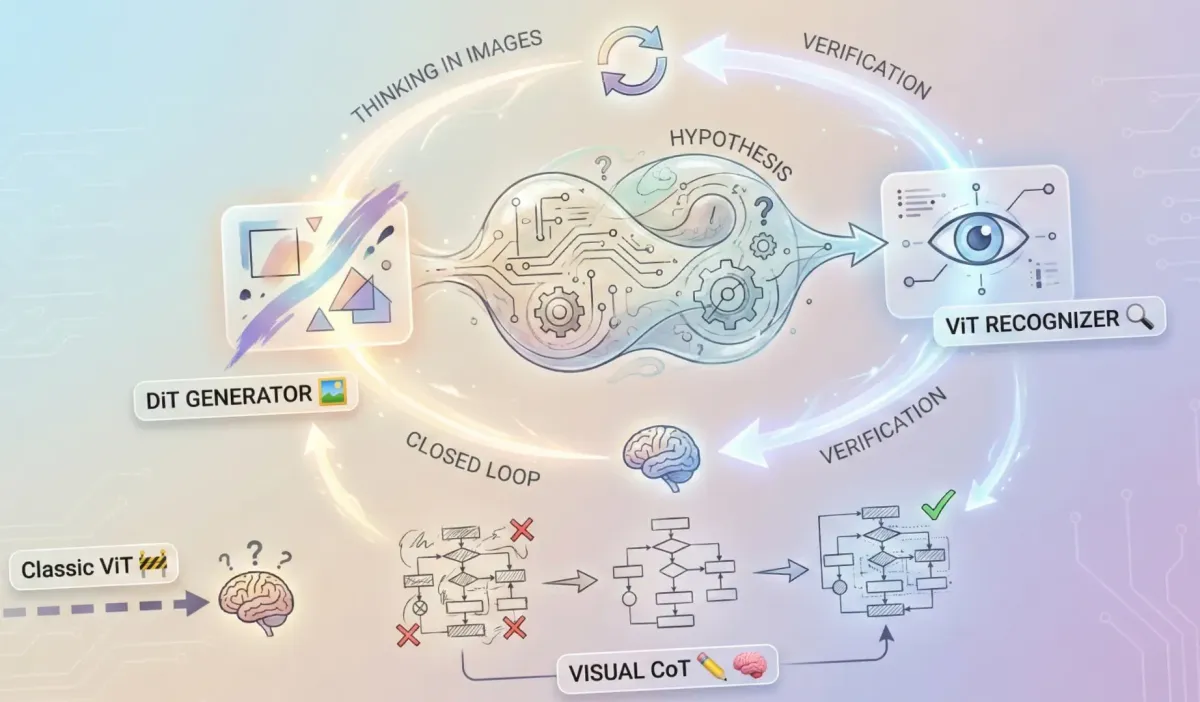
The key shift in Gemini 3: ViT is no longer a dumb sensor 🔄
DiT ⇄ ViT iteration as a verification loop
In Gemini 3, vision works differently. The image generator (DiT) and the recognizer (ViT) are not two separate services. They form a closed loop.
At a high level, it works like this:
1/ The model forms a hypothesis about the scene or solution.
2/ It generates an intermediate image (DiT).
3/ It runs this image back through ViT and checks whether the result matches the task.
4/ It repeats this for several steps - this is Visual Chain of Thought (Visual CoT).
The important part is not that the model can "draw images for humans".
It constantly generates images for itself, to check whether its internal understanding matches visual reality.
This is a qualitative change: ViT becomes part of a loop
"understand → simulate → verify".
Visual CoT: the model literally draws its thinking ✏️🧠
Chain of Thought beyond text
Text-based CoT is already familiar: the model writes intermediate steps to stabilize reasoning.
Visual CoT does the same, but:
- intermediate states include images, not only text
- the model must align visual and textual hypotheses
- reasoning becomes truly multimodal, not purely verbal
In practice, this enables new modes:
- messy handwritten text: the model can synthesize a "clean" version and check if it matches the original
- charts and trends: it can draw possible continuations and test consistency with labels
- layout problems: it can generate several scene configurations and check for collisions
This is no longer "recognize an object in an image", but
"manipulate a visual hypothesis until it no longer contradicts the constraints".
Why this creates benchmark gaps 📊
Benchmarks are a side effect of architecture
Benchmarks like ARC-AGI-2 and MMMU-Pro require constructive reasoning, not pattern recognition.
Gemini 3:
- improves ARC-AGI-2 results by several times compared to earlier versions
- clearly leads on MMMU-Pro and Video-MMMU, where text, image, and context must be combined
But the deeper reason is that the model can:
- build and test visual hypotheses
- align text and image through iterative loops
- run "mental experiments" at the image level, not only at the sentence level
Most other models still operate like this:
ViT: "image → vectors"
LLM: "vectors + text → answer"
Without the step: "let's try to reconstruct the image and see if we are lying to ourselves".
Where this matters most 🎯
1. Complex documents and handwriting 📄✍️
Document processing was long considered almost solved: OCR + layout + hacks.
In reality, it is messy:
- semi-handwritten forms
- overlapping notes
- non-standard tables and diagrams
- blurred or damaged scans
Gemini 3 shows that a model can not only recognize text, but reconstruct the logical structure of a document, including complex diagrams, and verify itself.
Meaning: instead of "OCR → post-processing", you can build pipelines where the model keeps both text and visual versions and cross-checks them.
2. Medical and biological images 🧬🩺
In medicine, CNNs and ViTs often act as black boxes. Results are domain-sensitive and unstable across datasets.
A model that can:
- build visual hypotheses about structures or pathologies
- simulate multiple visual scenarios ("if X, it looks like this; if Y, like that")
- align them with textual descriptions and protocols
gains a different kind of robustness.
This does not solve regulation or validation, but architecturally it is a system that can doubt its first visual interpretation and verify it via generation.
3. Spatial tasks and robotics 🤖📦
Any task involving:
- rearranging objects
- planning safe movement
- checking for collisions
benefits from a model that can generate and verify alternative scene configurations visually.
DiT + ViT lets AI do what engineers do mentally:
"imagine turning the object → see it collide → try another angle".
Monopoly or just a new normal? ⚖️
Google has a temporary lead, not magic
Fact: in open benchmarks, Gemini 3 currently leads in visual and multimodal reasoning.
But:
- The DiT ⇄ ViT + Visual CoT approach is not vendor-locked. It already exists in academic literature.
- Other vendors lag mainly because their vision pipelines were built as "services around LLMs", not deeply integrated into the core.
When others:
- build their own generation ⇄ recognition loops
- train models to reason via visual hypotheses
- stop treating ViT as a simple "feature extractor"
the gap will shrink.
For now, Google did what others postponed:
they turned vision into a full thinking tool.
Practical takeaways 🛠️
If you build products on top of models
- Do not treat images as "just another input type".
Use them to force the model to verify its hypotheses. - Design pipelines with visual intermediate steps.
Even without DiT, you can: - generate diagrams via SVG / Graphviz / canvas
- feed them back into the model
- Avoid "ViT wrapper + LLM core" for hard reasoning.
Fine for OCR, bad for thinking.
If you design multimodal models
- Make the ViT ⇄ generator loop part of training.
Teach the model to interpret and verify its own images. - Integrate Visual CoT in training and inference.
Visual CoT datasets show strong gains in reasoning quality. - Test on constructive tasks, not only recognition.
ARC-AGI-2 and MMMU-Pro are sanity checks for real thinking.
If you make strategic decisions (PM / CTO)
- Do not treat all multimodal models as equal.
"Image support" can mean very different capabilities. - Ask engineering questions, not marketing ones.
For example: - Can the model generate intermediate visual states?
- Does it support Visual CoT?
- How is the ViT ⇄ generation loop implemented?
- Design products to be vendor-switchable.
Today Google leads; tomorrow the balance may change.
Conclusion 🧩
Gemini 3 moved ahead not because of "more data", but because vision changed its role: from a sensor to a tool for forming and testing hypotheses.
The DiT ⇄ ViT loop and Visual CoT bring machine reasoning closer to how engineers think: not only with words, but with drawings.
If we keep seeing multimodal models as "LLMs that also understand images", we will build yesterday's products. A better frame is this:
vision is not an input channel - it is a space where the model thinks.
A good first step is to redesign pipelines so the model has visual intermediate steps and the ability to check itself, not just produce a nice screenshot.
🙂 Fun fact: what do Gemini 3 and an engineer with a notebook have in common?
Both think better when they can draw - and check if they are fooling themselves.
Sources
1/ https://blog.google/technology/developers/gemini-3-pro-vision
2/ https://docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/3-pro
3/ https://vellum.ai/blog/google-gemini-3-benchmarks
4/ https://reddit.com/r/singularity/comments/1pec4zg/gemini_3_deep_think_benchmarks_released_hits_451
